
正規表現は、文字のパターンを指定して検索や置換を行うための強力なツールです。たとえば、「メールアドレスの形式に当てはまるものだけを抽出する」といった、複雑な検索もたった1行で実現できます。この記事では、正規表現の基本的な使い方を、わかりやすく解説していきます。
正規表現の基本
基本的な記号
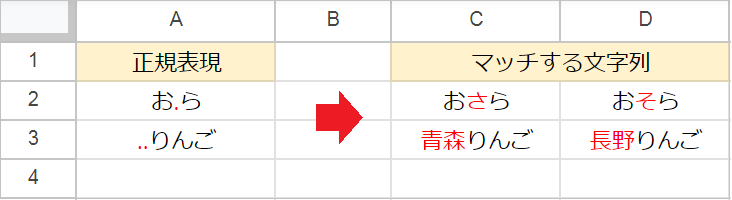
.(任意の1文字)- 改行以外のどんな文字でも1文字として捉えます。つまり、
..なら任意の2文字を表します。
- 改行以外のどんな文字でも1文字として捉えます。つまり、

[](文字セット)- 文字セットの中に書かれた文字の、いずれか1つにマッチすることを表します。

|(または)- または(OR)を意味し、左右どちらかのパターンにマッチします。
繰り返しの記号(数量詞)

*(0回以上)- 直前の文字が「なくてもいいし、何個あってもいい」ことを意味します。

+(1回以上)- 直前の文字が「最低1回は必要で、何回でも繰り返してもいい」ことを意味します。

?(0回か1回)- 直前の文字が「0回か1回だけ繰り返す」ことを意味します。

{n}:ちょうどn回- 直前の文字がちょうどn回繰り返されるパターンにマッチします。
{n,}:n回以上- 直前の文字がn回以上繰り返されるパターンにマッチします。
{n,m}:n回からm回まで- 直直前の文字がn回からm回まで繰り返されるパターンにマッチします。
文字の位置を指定する記号

^(先頭)- 文字列の先頭が
^に続く文字列で始まることを意味します。
- 文字列の先頭が

$(末尾)- 文字列の末尾が
$の直前の文字列で終わることを意味します。
- 文字列の末尾が
文字の種類を指定する記号
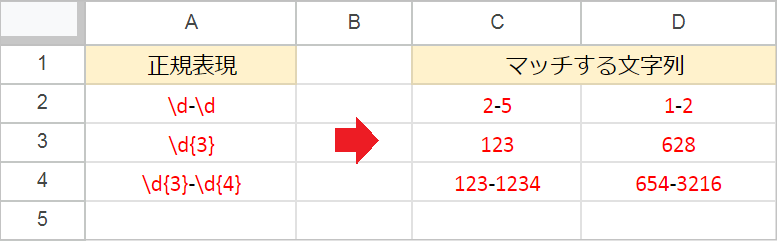
\d(半角数字)- 「半角数字(0〜9)にマッチする」ことを意味します。
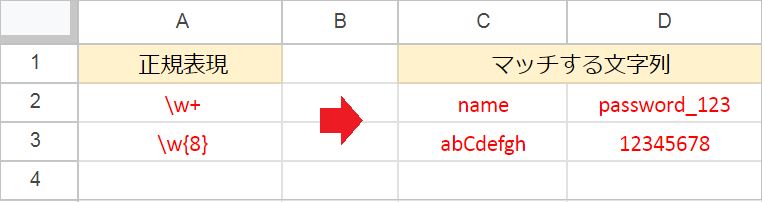
\w(半角英数字とアンダースコア)- 「半角英数字(0-9A-Za-z_)にマッチする」ことを意味します。
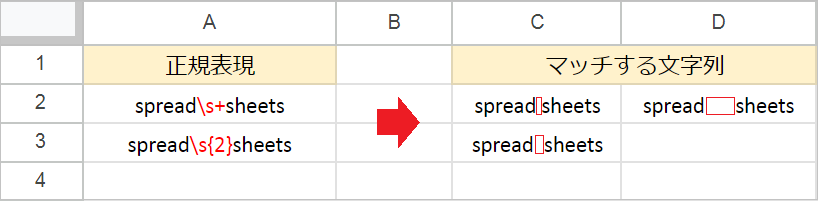
\s(半角スペース)- 空白文字(半角スペース、タブ、改行など)にマッチすることを意味します。
グループ化と抽出

()(キャプチャグループ)- 特定のパターンをまとめることを意味し、特定のまとまり(グループ)を繰り返したり、抽出したりできます。
最短一致と最長一致
最長一致(なるべく長く)

.*(任意の0文字以上)- 任意の文字が0文字以上続くパターンに、できるだけ長く一致しようとします。
.+(任意の1文字以上)- 任意の文字が1文字以上続くパターンに、できるだけ長く一致しようとします。
最短一致(なるべく短く)
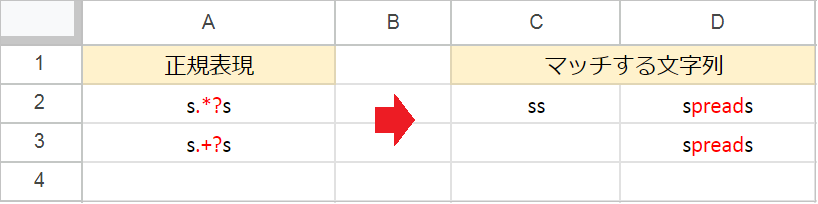
.*?(任意の0文字以上)- 任意の文字が0文字以上続くパターンに、できるだけ短く一致しようとします。
.+?(任意の1文字以上)- 任意の文字が1文字以上続くパターンに、できるだけ短く一致しようとします。
正規表現を活用する関数
REGEXEXTRACT関数(抽出)

REGEXEXTRACT関数は、指定したテキストの中から、正規表現で指定したパターンに最初に合致する部分の文字列を抽出します。
たとえば、A列のメールアドレスから「@より前の部分」だけを抽出したい場合は、以下のようになります。
例:=REGEXEXTRACT(A1,"(.*)@")
この数式では、「@より前の任意の文字列」を正規表現で指定し、その部分だけを抽出しています。
REGEXEXTRACT関数の引数:(テキスト, 正規表現)
REGEXREPLACE関数(置換)

REGEXREPLACE関数は、文字列の中から特定のパターンに一致する部分を検索し、別の文字列に置き換えます。
たとえば、A列のテキストの中からxをaに置換したい場合、数式は次のようになります。
例:=REGEXREPLACE(A2,"x","a")
REGEXREPLACE関数は、このように単純な文字の置き換えにも使うことができますが、正規表現を使うことで、より複雑なパターンにも対応できるようになります。
REGEXREPLACE関数の引数:(テキスト, 正規表現, 置換後の文字列)
REGEXMATCH関数(判定)
REGEXMATCH関数は、指定したテキストが正規表現で指定したパターンに合致するかどうかを判定し、結果をTRUEまたはFALSEで返します。このTRUEやFALSEという判定結果を、他の関数と組み合わせることで、複雑な条件でのデータ検索が実現できます
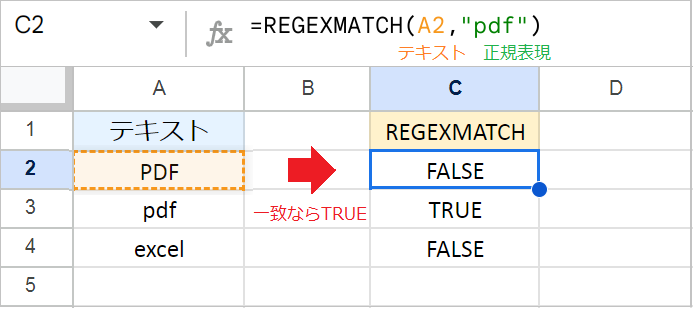
たとえば、A列のテキストが「pdf」という文字列と一致するかどうかを判定する場合、次の数式を使用します。
例:=REGEXMATCH(A2,"pdf")
このように、REGEXMATCH関数は大文字と小文字を区別するため、「PDF」ならFALSEを、「pdf」ならTRUEを返します。
REGEXMATCH関数の引数:(テキスト, 正規表現)
正規表現の一覧
| 記号/パターン | 意味 | 使用例 | マッチする例 |
| . | 任意の1文字 | a.b | acb, aab |
| [xyz] | []内のいずれか1文字(例: [abc]) -で範囲指定も可能(例: [0-9], [a-z]) | [aeiou] | a, e, i, o, u |
| [^xyz] | []内の文字以外の1文字 -で範囲指定も可能(例: [^0-9]) | [^abc] | d, 1, ! |
| \d | 半角数字([0-9]と同じ意味) | \d{3} | 123 |
| \D | 半角数字以外の1文字([^0-9]と同じ意味) | \D+ | abc, りんご |
| x|y | xまたはyのいずれかの文字列 | cat|dog | cat, dog |
| * | 直前の文字の0回以上の繰り返し | ab*c | ac, abc, abbbc |
| + | 直前の文字の1回以上の繰り返し | ab+c | abc, abbbc |
| ? | 直前の文字の0回または1回の繰り返し(0回か1回だけ) | colou?r | color, colour |
| .* | 任意の0文字以上の文字列できるだけ長く一致しようとする) | a.*B | axByB→ axByB にマッチ |
| .+ | 任意の1文字以上の文字列できるだけ長く一致しようとする) | a.+B | axByB→ axByB にマッチ |
| .*? | 0文字以上の任意の文字列(できるだけ短く一致しようとする) | a.*?B | axByB → axB にマッチ |
| .+? | 1文字以上の任意の文字列(できるだけ短く一致しようとする) | a.+?B | axByB → axB にマッチ |
| ^ | 文字列の先頭 | ^Apple | Apple pie |
| $ | 文字列の末尾 | Apple$ | Red Apple |
| \s | 空白文字(半角スペース、タブ、改行など) | Hello\sWorld | Hello World |
| \S | 空白文字以外の1文字 | \S+ | abc |
| \w | 半角英数字とアンダースコア([0-9A-Za-z_]と同じ) | \w+ | my_document_1 |
| \W | 半角英数字とアンダースコア以外の1文字 | \W | !, ?, あ |
| () | グループ化(特定のパターンをまとめる) 例: (ab)+ で ab, abab にマッチ | (ABC){2} | ABCABC |
| (?i) | 大文字小文字を区別しない(パターン全体に適用) | (?i)apple | Apple, apple, APPLE |
| {n} | 直前の文字のn回の繰り返し | \d{3} | 123 |
| {n,} | 直前の文字のn回以上の繰り返し | \d{3,} | 123, 12345 |
| {n,m} | 直前の文字のn回以上m回以下の繰り返し | \d{1,3} | 1, 12, 123 |
| \ | 直後の正規表現の記号を文字として検索する(エスケープ) | google\.com | google.com |