
GoogleスプレッドシートのREGEXEXTRACT関数は、通常の検索では難しい「特定のパターンに合致する文字列」を抽出するのに役立ちます。この記事では「正規表現」の基本的な記号から、具体的な使用例まで解説しているので、ぜひ参考にしてみてください。
REGEXEXTRACT関数とは

REGEXEXTRACT関数は、指定したテキストの中から、正規表現で指定したパターンに最初に合致する部分の文字列を抽出します。
たとえば、A2セルに「商品名:りんご」と入力されている場合に、商品名だけを抽出したい場合は以下のようになります。
例:=REGEXEXTRACT(A2,"商品名:(.+)")
この数式では、「商品名:」の後に続く任意の文字列(りんご)を正規表現で指定し、その部分だけを抽出しています。
REGEXEXTRACT関数の引数:(テキスト, 正規表現)
正規表現の基本的な記号
正規表現は、あいまいな文字列を検索するための手法の 1 つで、メタキャラクタ(メタ文字)という記号を使って、文字列のパターンを柔軟に表現します。
特に、以下の基本的な記号は抽出の際に頻繁に使われます。
.(ドット): 任意の1文字にマッチ
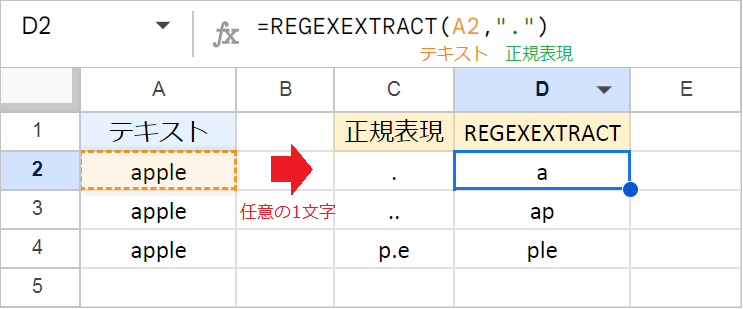
. は、改行以外のどんな文字でも1文字として捉えます。
- 例1:
=REGEXEXTRACT("apple",".")- 任意の1文字と最初に一致する
aが抽出されます。
- 任意の1文字と最初に一致する
- 例2:
=REGEXEXTRACT("apple","..")- 任意の2文字と最初に一致する
apが抽出されます。
- 任意の2文字と最初に一致する
- 例3:
=REGEXEXTRACT("apple","p.e")pとeの間に任意の1文字があるpleの部分が抽出されます。
* (アスタリスク): 直前の文字の0回以上の繰り返し
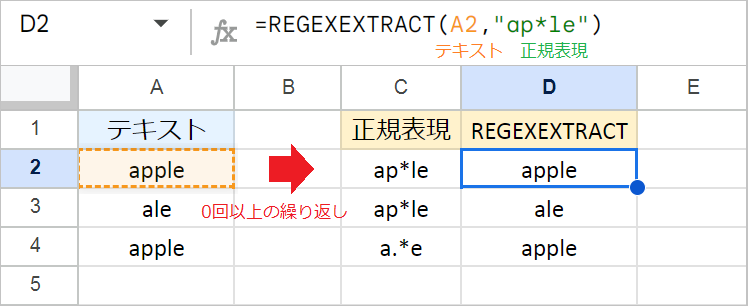
* は、直前の文字が「なくてもいいし、何個あってもいい」ことを意味します。
- 例1:
=REGEXEXTRACT("apple","ap*le")aとleの間にpが2回繰り返されるappleが抽出されます。
- 例2:
=REGEXEXTRACT("ale","ap*le")p*は0回にもマッチするため、aleから、aleが抽出されます。
- 例3:
=REGEXEXTRACT("apple","a.*e")aとeの間に任意の文字が0回以上繰り返されるappleが抽出されます。
+ (プラス): 直前の文字が1回以上の繰り返し

+ は、直前の文字が「最低1回は必要で、何回でも繰り返してもいい」ことを意味します。
- 例1:
=REGEXEXTRACT("apple","ap+le")aとleの間にpが2回繰り返されるappleが抽出されます。
- 例2:
=REGEXEXTRACT("ale","ap+le")p+はpが最低1回は必要なため、aleはマッチせずエラーになります。
- 例3:
=REGEXEXTRACT("apple","a.+e")aとeの間に任意の文字が1回以上繰り返されるappleが抽出されます。
{}(波括弧):繰り返し回数の指定
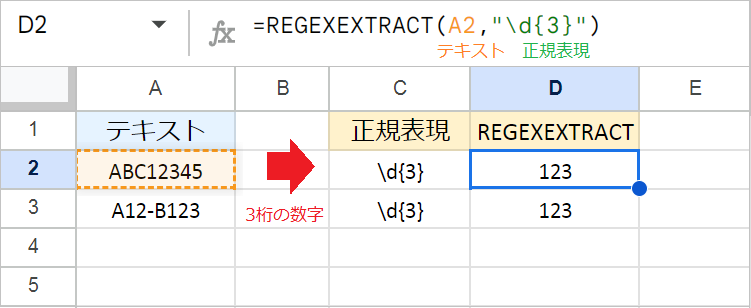
+や*が「1回以上」 や「0回以上」 のように上限を設けないのに対し、{}は繰り返しの回数を指定できます。
- 例1:
=REGEXEXTRACT("ABC12345","\d{3}")- 文字列の中にある「連続した3桁の数字」である
123が抽出されます。続く45は桁数が異なるため、無視されます
- 文字列の中にある「連続した3桁の数字」である
- 例2:
=REGEXEXTRACT("A12-B123","\d{3}")- 文字列の中にある「連続した3桁の数字」である
123が抽出されます。前にある12は2桁なので、パターンに合致せず無視されます。
- 文字列の中にある「連続した3桁の数字」である
\dは「数字(0〜9)にマッチする」ことを表す記号です。
() (丸括弧): 抽出したい部分をグループ化する
特定の部分だけを抽出する
() は「グループ化」を表し、REGEXEXTRACT関数はこのグループに合致した部分だけを抽出します。これにより、正規表現全体がマッチした部分から、特定の要素だけを抜き出せます。

- 例1:
=REGEXEXTRACT("ID-ss","(.+)-")- ハイフン
-より前の「任意の1文字以上」(ID)をグループ化しています。これにより、IDの部分だけが抽出されます。
- ハイフン
- 例2:
=REGEXEXTRACT("ID-ss","-(.+)")- ハイフン
-より後ろの「任意の1文字以上」(ss)をグループ化しています。これにより、ssの部分だけが抽出されます。
- ハイフン
複数の結果を同時に抽出する
REGEXEXTRACT関数は、正規表現の中に複数の()(キャプチャグループ)を設定することで、複数の結果を同時に異なるセルへ抽出できます。これは、テキストを複数のデータ項目に分解したい場合に便利です。

- 例3:
=REGEXEXTRACT("ID-ss","(.+)-(.+)")- 複数の
()(グループ)を使って、ハイフン-で区切られた2つの結果を抽出します。最初の(.+)がIDを、次の(.+)がssをそれぞれグループとして別々のセルに抽出されます。
- 複数の
複数のパターンにマッチさせる
| (パイプ): いずれかのパターンにマッチ
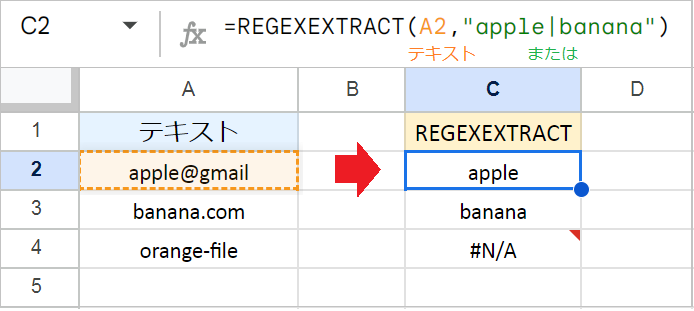
| は「または(OR)」を意味し、左右どちらかの正規表現パターンにマッチします。
たとえば、次の数式はA列のテキストから、appleまたはbananaのいずれかの単語を抽出します。
例:=REGEXEXTRACT(A2,"apple|banana")
apple@gmailという文字列の中に、パターンに含まれるappleがあるので、それが抽出されます。
[] (角括弧): 文字セットのいずれか1文字にマッチ
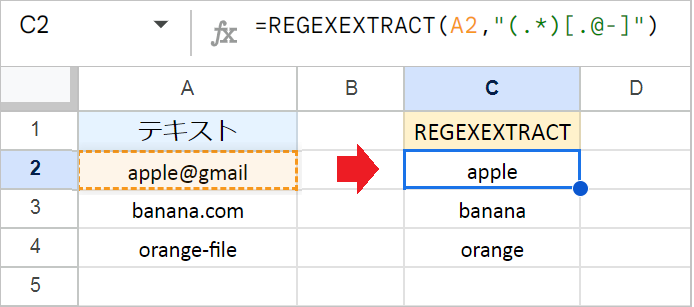
[] (角括弧)は文字セットを表し、その中に書かれた文字のいずれか1つにマッチします。
たとえば、次の数式はA列のテキストから、@、.、または-のいずれか1文字より前の部分を抽出します。
例:=REGEXEXTRACT(A2,"(.*)[.@-]")
(.*)で任意の0文字以上をグループ化し、その直後に[.@-](ドット、アットマーク、またはハイフンのいずれか1文字)が続くパターンにマッチします。
REGEXEXTRACT関数の使用例
メールアドレスからドメイン名を抽出する
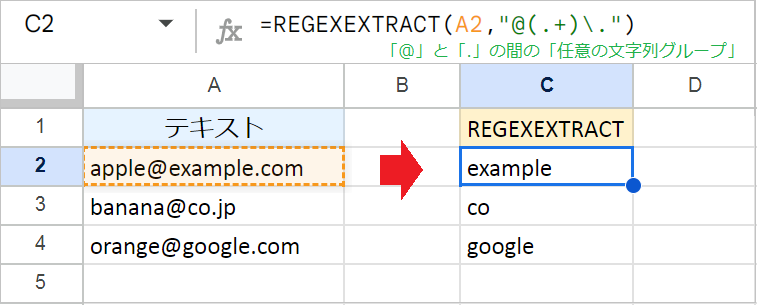
メールアドレスからドメイン名だけを抜き出したい場合は、.(任意の文字)、+(繰り返し)、()(キャプチャグループ)、\(エスケープ)を組み合わせます。
例:=REGEXEXTRACT(A2,"@(.+).")
@と\.(エスケープされたドット)で抽出範囲を指定し、(.+) で、その間にある任意の文字列を抽出しています。このとき.(ドット)だけだと正規表現の「任意の1文字」と認識されるため、\を付けて正規表現としての効果をエスケープしています。
住所から都道府県名を抽出する
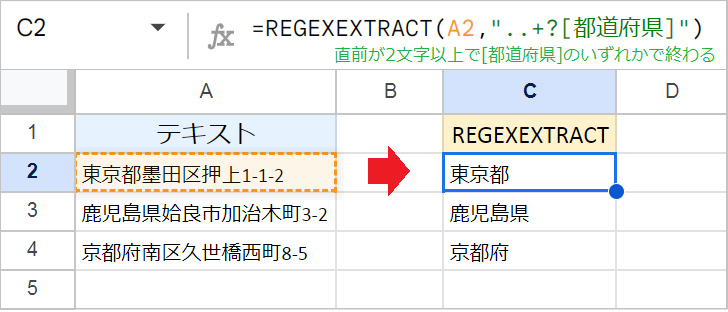
住所から都道府県名だけを抜き出したい場合は、.(任意の文字)、+(繰り返し)、?(最短一致)、[](文字セット)を組み合わせます。
例:=REGEXEXTRACT(A2,"..+?[都道府県]")
この数式では、.. で都道府県名の前に最低2文字があることを指定しています。これにより、「京都」 のような2文字の文字列にマッチしないようにしています。
また、? で最短一致を表すことで、「京都府京都」のような文字列にマッチしないようにしています。

さらに先ほどの正規表現に(.*)を付け加えることで、それ以降の文字列をグループ化して抽出できます。
例:=REGEXEXTRACT(A2,"(..+?[都道府県])(.*)")
電話番号から数字だけ抽出する
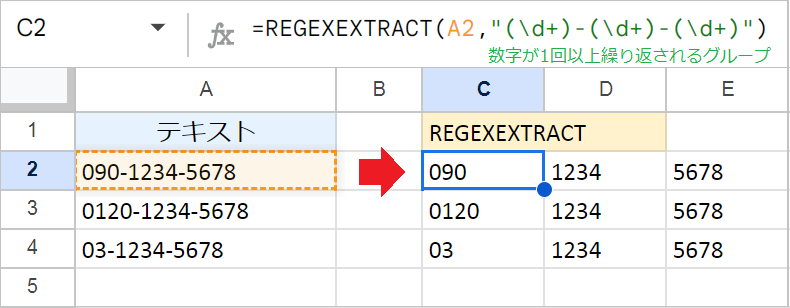
電話番号に含まれるハイフンなどの記号を無視して、数字の塊だけを抽出したい場合は、\d(数字)と+(繰り返し)、()(キャプチャグループ)を組み合わせます。
例:=REGEXEXTRACT(A2,"(\d+)-(\d+)-(\d+)")
(\d+)は「数字が1回以上繰り返されるグループ」を表します。この数式では、ハイフンを挟んだ3つの数字の塊をそれぞれグループ化することで、それぞれ別々のセルに抽出されます。