
GoogleスプレッドシートのCOUNTIF関数は、「大文字と小文字」を区別しません。「Appleとapple」を区別してカウントしたい場合、他の関数を組み合わせて実現します。この記事では、大文字と小文字を区別してCOUNTIF関数のようにカウントする方法から、部分一致の検索まで詳しく解説します。
はじめに
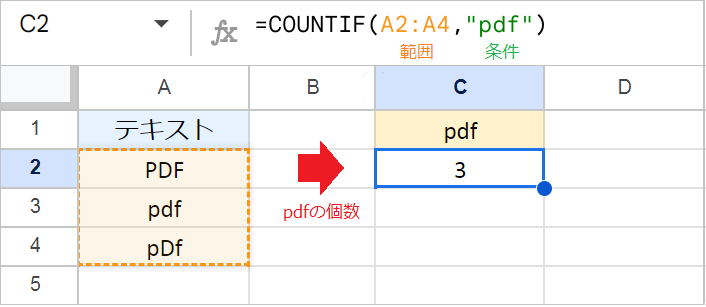
COUNTIF関数は「検索範囲」から指定した「条件」と一致するセルの個数を返します。
たとえば、A列のテキストの中から「pdf」という文字列のセルを数えたい場合は、次の数式を使います。
例:=COUNTIF(A2:A4,"pdf")
このとき、COUNTIF関数はデフォルトで「大文字と小文字」を区別しません。 そのため、「PDF」「pdf」「pDf」のどれがA列にあっても、集計対象としてカウントします。
COUNTIF関数の引数:(範囲, 条件)
COUNTIF:大文字・小文字を区別してカウントする
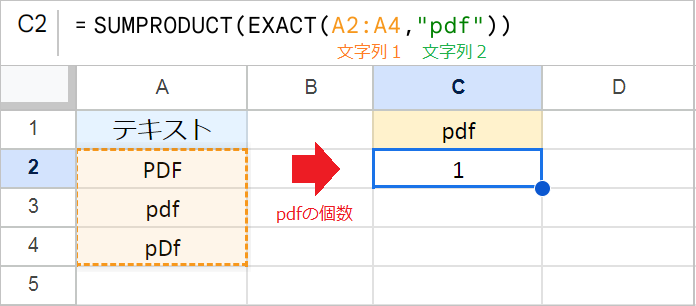
大文字と小文字を区別して数えたい場合は、SUMPRODUCT関数とEXACT関数を組み合わせます。
たとえば、A列のテキストの中から「pdf」と完全に一致する文字列を数えたい場合は、次の数式を使います。
例:=SUMPRODUCT(EXACT(A2:A4,"pdf"))
この数式では、EXACT関数で2つの文字列が同一であるかを検証し、その結果を{FALSE; TRUE; FALSE}のような配列で返します。SUMPRODUCT関数は、この配列を{0; 1; 0}という数値に変換して合計します。
SUMPRODUCT関数の引数:(配列1, [配列2, …])
COUNTIF:部分一致で厳密に検索する

COUNTIFは、ワイルドカード(*や?)を使って部分一致を検索できますが、その場合も大文字と小文字を区別しません。
もし、部分一致でこれらを区別したい場合は、SUMPRODUCT関数とREGEXMATCH関数を組み合わせます。
たとえば、A列のテキストの中から「p」という文字列で始まるもの(大文字・小文字を区別して)を数えたい場合は、次の数式を使います。
例:=SUMPRODUCT(REGEXMATCH(A2:A4,"^p"))
の数式では、REGEXMATCH関数が各セルの文字列が指定の正規表現(この場合は「pで始まる」)にマッチするかを判定し、{FALSE; TRUE; FALSE}のような配列を返します。SUMPRODUCT関数は、この配列を{0; 1; 0}という数値に変換して合計します。
その他の便利な正規表現の例
- 〜を含む:
"pdf" - 〜で終わる:
"pdf$" - 〜を含まない:
NOT(REGEXMATCH(A2:A4,"pdf"))
REGEXMATCH関数の引数:(テキスト, 正規表現)