
Googleスプレッドシートでは、INDEX関数とMATCH関数を組み合わせることで、より柔軟なデータ抽出が可能です。この記事では、それぞれの関数の使い方から、データをクロス抽出する基本のテクニックについて解説しているので、ぜひ参考にしてみてください。
INDEX関数の使い方
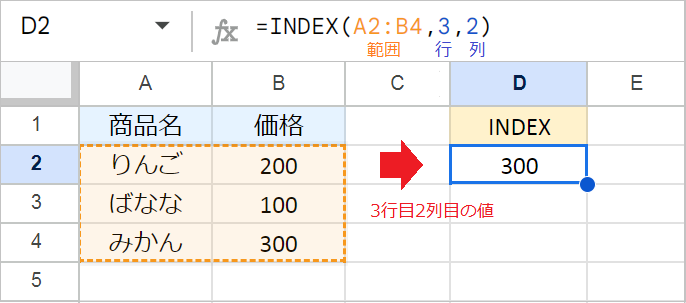
INDEX関数は、指定した範囲から、行と列がクロスするセルの値を返します。
たとえば、A2:B4の範囲から、3行目と2列目が交差するセルの値を抽出したい場合、数式は次のようになります。
例:=INDEX(A2:B4,3,2)
ポイント
A2:B4の範囲で数えるため、左上のA2セルが1行目、1列目となります。この数式は、A2を基点に3行目と2列目が交差するB4セルの値を返します。
INDEX関数の引数:(参照, [行], [列])
特定の行や列全体を抽出する
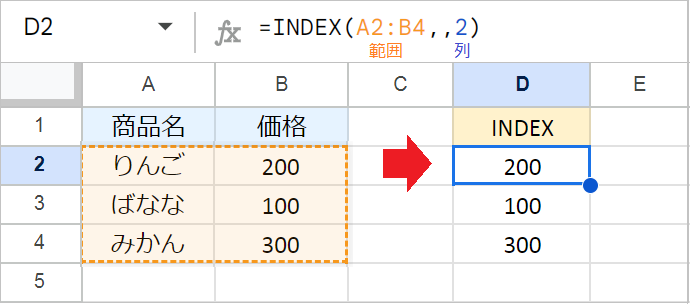
INDEX関数の第2引数(行)と第3引数(列)はどちらも省略できます。
たとえば、次のように「行」を省略すると、指定した列のすべての値を抽出します。
例:=INDEX(A2:B4,,2)
MATCH関数の使い方

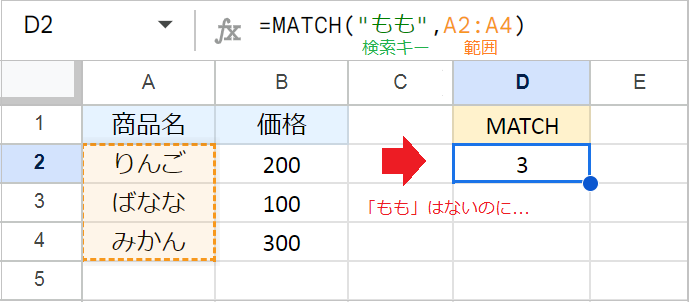
MATCH関数は、指定した範囲の中で、検索キーの相対的な位置を検索します。
たとえば、A2:A4の範囲から、「ばなな」が何番目にあるかを検索したい場合、数式は次のようになります。
例:=MATCH("ばなな",A2:A4,0)
ポイント
この数式は、A2を基点に「ばなな」が上から何番目にあるかを返します。この場合、返り値は「2」となります。
MATCH関数の引数:(検索キー, 範囲, [検索の種類])
検索の種類について
MATCH関数の第3引数である[検索の種類]には、1、0、-1のいずれかを指定します。
もし「検索の種類」を省略すると、1が指定されたものとみなされ、予期せぬ結果になることがあります。そのため、通常は必ず0を指定します。
0(完全一致):検索キーと完全に一致する値を検索します。1(以下):範囲が昇順に並んでいる前提で、検索キー以下の最も大きい値を検索します。-1(以上):範囲が降順に並んでいる前提で、検索キー以上の最も小さい値を検索します。
INDEXとMATCHを組み合わせる
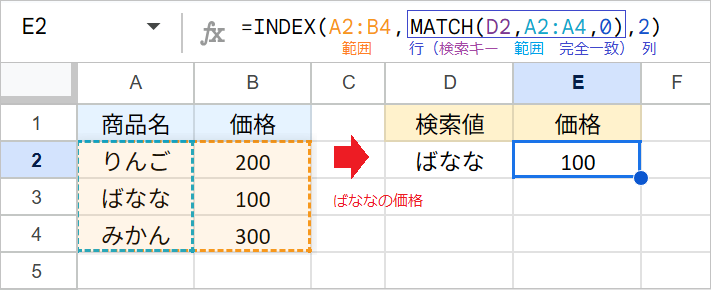
最も基本的となるのが、INDEX関数とMATCH関数を組み合わせて、行と列のクロスする値を抽出する方法です。
たとえば、A列の商品名から「ばななの価格」を抽出したい場合、数式は次のようになります。
例:=INDEX(A2:B4,MATCH(D2,A2:A4,0),2)
数式の解説
- MATCH関数:
A2:A4の範囲で、ばななが何番目にあるかを検索します。 - INDEX関数:MATCH関数の結果(2番目)を行番号として、2列目(
B2:B4)の2行目の値(100)を返します。
INDEXとMATCHを使うメリット
VLOOKUP関数でも検索値と一致する値を抽出できますが、INDEX関数とMATCH関数を組み合わせて使うことで、次のようなメリットがあります。
列の挿入や削除に強い:MATCH関数が自動で列の位置を計算するため、途中に列を挿入したり削除したりしても数式が壊れません。
柔軟性が高い:VLOOKUP関数は、検索キーが範囲の1列目に限定されますが、INDEX関数はMATCH関数を組み合わせることで、どの列でも検索キーに指定できます。
処理速度が速い:INDEX関数は、MATCH関数が返した「位置」の情報を使って、指定されたセルに直接アクセスします。そのため、データ量が膨大になった場合でも、処理が速くなります。
【応用】INDEXとMATCHを複数条件にする
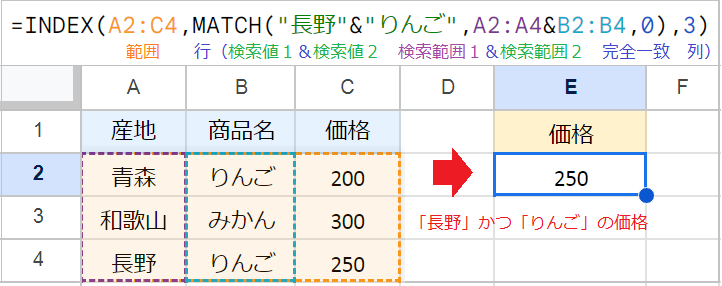
複数の条件と一致する値を抽出したい場合、検索値同士と範囲同士を&で結合します。
たとえば、A2:C4の範囲から、「A列が青森」かつ「B列がりんご」の価格を抽出したい場合、数式は次のようになります。
例:=INDEX(A2:C4,MATCH("長野"&"りんご",A2:A4&B2:B4,0),3)
検索値をセル参照にして数式をコピーしたい場合は、検索値以外のすべての参照範囲を絶対参照($を付ける)で固定します。
例:=INDEX($A$2:$C$4,MATCH(E2&F2,$A$2:$A$4&$B$2:$B$4,0),3)
よくある質問
条件に一致するデータをすべて抽出したい
結果として複数の値を抽出したい場合、FILTER関数が便利です。
別シートのデータを参照したい
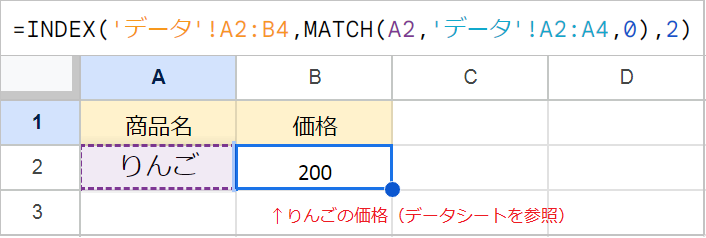
別シートを参照したい場合、'シート名"!A2:B4のように範囲の前にシート名を追加します。
例:=INDEX('データ'!A2:B4,MATCH(A2,'データ'!A2:A4,0),2)
別のスプレッドシートを参照したい場合は、IMPORTRANGE関数を使ってデータを取り込む必要があります。詳しくは「IMPORTRANGE関数の使い方」をご覧ください。
具体的な使用例を知りたい
- クロス抽出する:行と列の2つの条件を指定し、クロスする位置の値を抽出します。
- 例:
=INDEX(B2:C4, MATCH(D1, A2:A4, 0), MATCH(D2, B1:C1, 0))
- 例:
- 検索値の1つ下のセルを抽出する:索値の位置を特定した後、そのセルから相対的にずれた位置の値(例:1つ下のセル)を抽出できます。(詳細記事はコチラ)
- 文字列の最頻値を求める:複雑なデータから特定の値が最も多く出現する位置を特定するために応用できます。(詳細記事はコチラ)
まとめ
INDEX関数とMATCH関数を組み合わせることで、VLOOKUP関数よりも柔軟で、処理速度が速いデータ抽出が可能になります。
それぞれの関数の役割は以下の通りです。
- INDEX関数: 行と列のクロスする位置の値を抽出
- MATCH関数: 検索キーの位置を検索
この組み合わせを使うメリットは次のとおりです。
- 柔軟性の高さ: 検索キーの列がどこにあってもデータを抽出できます。
- 処理速度の速さ: データ量が増えても、効率的に処理ができます。
- メンテナンス性の良さ: 途中に列を挿入・削除しても、数式が壊れません。