
エクセルやスプレッドシートで、テキスト内から特定の文字以前や以降だけを抽出する方法をご紹介します。LEFT・RIGHT・MID関数の基本的な使用方法から、特定の文字列だけを抽出する方法についても解説しているので、ぜひ参考にしてみてください。
LEFT関数で特定の文字より前を抽出する方法
特定の文字以前を抽出するには、LEFT関数を使用します。FIND関数と組み合わせれば、先頭からどの文字までを抽出するのか指定することも可能です。
左から指定文字数を抽出する方法
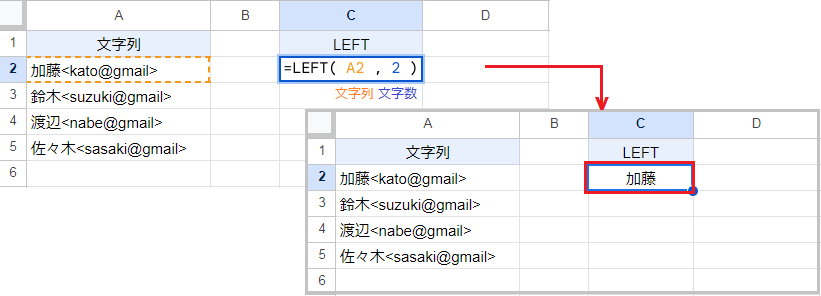
LEFT関数は文字列の先頭から、指定した文字数を返します。
例えば LEFT(A2,2) なら文字列の先頭から2文字を抽出するので、返り値は「加藤」です。文字数を省略すると、先頭から1文字を返します。
LEFT関数の構造:(文字列, [文字数])
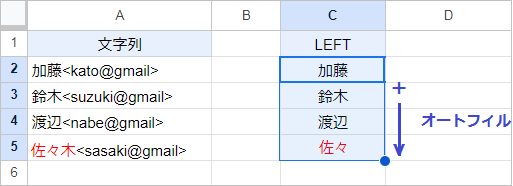
C2セルに入力したLEFT関数を、オートフィルで下までコピーします。
するとA5セルの「佐々木」さんが、「佐々」になってしまいました。これはLEFT関数に、文字列の左から2文字を抽出するように設定したためです。
このような場合、次にご紹介する「左から特定の文字列を抽出する方法」で解決できます。
-
オートフィルとは?
-
数式や連続した値をコピーする機能です。セルの右下にカーソルを合わせると「+」マークになるので、この状態でクリックしたままコピーしたい方向に引っ張ります。
左から特定の文字列を抽出する方法
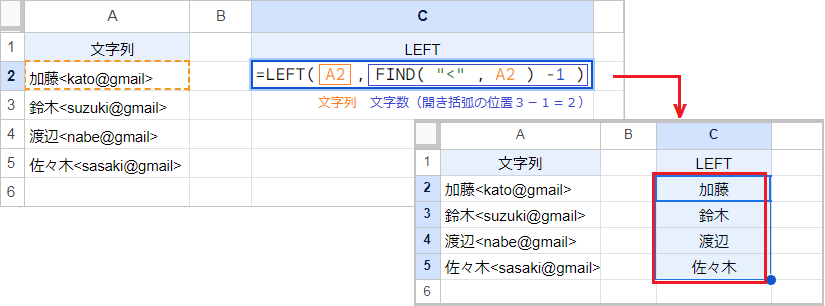
FIND関数は検索文字列を対象の文字列から検索し、左端から数えたときの番号を返します。
例えば FIND(“<“,A2)-1 なら、返り値は開き括弧の位置(3)-1=2 です。
これをLEFT関数の文字数に指定すると、LEFT(A2,FIND(“<“,A2)-1) になります。LEFT関数は開き括弧より前の文字列を左から抽出するので、文字数の異なる名前を抽出可能です。
FIND関数の構造:(検索文字列, 対象, [開始位置])
[開始位置]には、検索を開始する位置を指定可能です。 省略すると先頭から検索されます。
RIGHT関数で特定の文字以降を抽出する方法
文字列を末尾から取り出すには、RIGHT関数を使用します。FIND関数やLEN関数と組み合わせれば、右から特定の文字までを抽出することも可能です。
右から指定文字数を抽出する方法
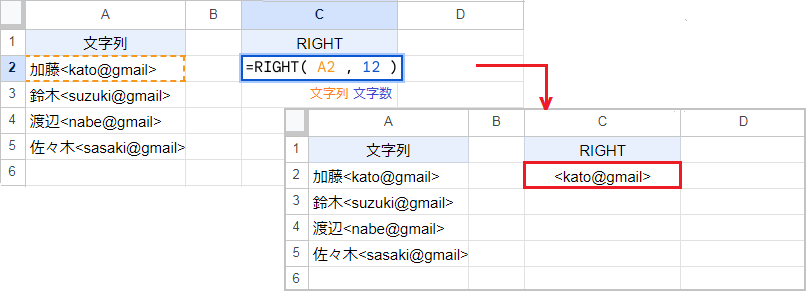
RIGHT関数は文字列の末尾から、指定した文字数を返します。
例えば RIGHT(A2,12) なら文字列の末尾から12文字を抽出するので、返り値は<kato@gmail> です。文字数を省略すると、末尾から1文字を返します。
RIGHT関数の構造:(文字列,[文字数])
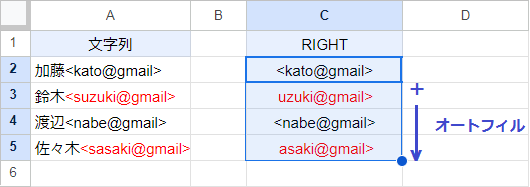
C2セルに入力したRIGHT関数を、オートフィルで下までコピーします。
すると鈴木さんと佐々木さんのアドレスが、正しく入力されていません。これはRIGHT関数で、テキストの末尾から12文字を抽出するように設定したためです。
このような場合、次にご紹介する「右から特定の文字列を抽出する方法」で解決できます。
右から特定の文字列を抽出する方法
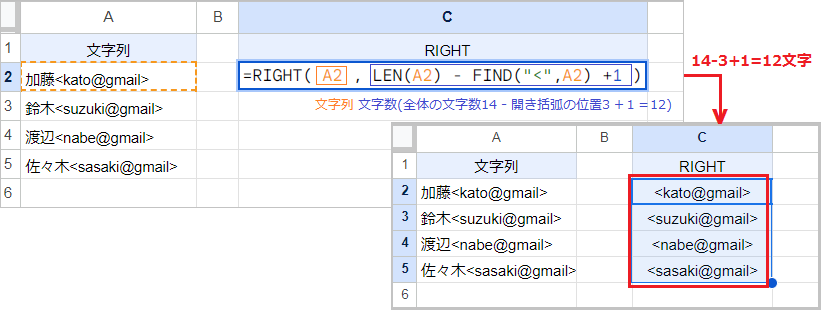
LEN関数は全体の文字数を、FIND関数は開き括弧の位置を返します。
つまり LEN(A2)-FIND(“<“,A2)+1 なら、返り値は 14-3+1=12 です。これをRIGHT関数の文字数に指定すると、RIGHT(A2,LEN(A2)-FIND(“<“,A2)+1) になります。
RIGHT関数は右から開き括弧までの文字列を抽出するので、アドレス部分を抽出可能です。
LEN関数の構造:(文字列)
FIND関数の構造:(検索文字列, 対象, [開始位置])
MID関数で特定の文字を抽出する方法
特定の文字を抽出するには、MID関数使用します。FIND関数やLEN関数と組み合わせれば、開始位置や文字数を自動調整することも可能です。
特定の文字を抽出する方法
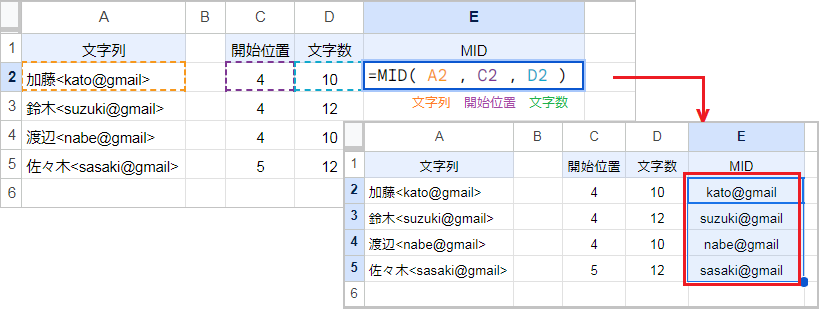
MID関数は文字列の開始位置から、指定した文字数を返します。
例えば MID(A2,C2,D2) なら文字列の4文字目から10文字を返すので、返り値は kato@gmail です。
MID関数の構造:(文字列, 開始位置, 文字数)
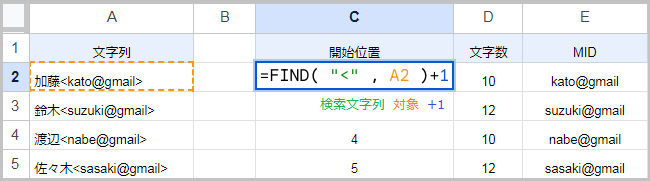
まずFIND関数で、抽出する文字の開始位置を取得します。
括弧内より右側を開始位置とするなら、FIND(“<“,A2)+1 です。FIND関数は検索文字列の位置を返すので、開き括弧の位置(3)+1=4 になります。
FIND関数の構造:(検索文字列, 対象, 開始位置(省略可))
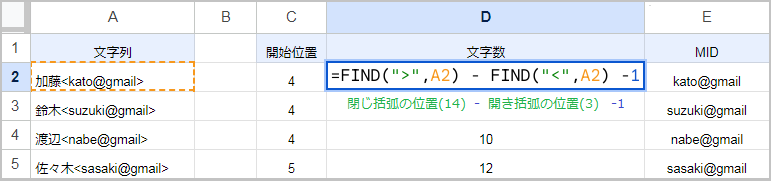
次に終了位置から開始位置を減算することで、抽出する文字数を取得します。
閉じ括弧の左側を終了位置とするなら、FIND(“>”,A2)-FIND(“<“,A2)-1 です。
これらをMID関数の開始位置と文字数に当てはめると、MID(A2,FIND(“<“,A2)+1,FIND(“>”,A2)-FIND(“<“,A2)-1)になります。
