
Googleスプレッドシートで特定の文字列から、数字または文字列だけ抽出する関数をご紹介します。REGEXREPLACE関数でよく使用するその他の正規表現や、合計値から数字だけコピーするショートカットキーについても解説しているので、ぜひ参考にしてみてください。
文字列から数字だけ抜き出す方法
REGEXREPLACE関数の正規表現に、数字または文字を指定する方法をご紹介します。今回は新しい文字列に空白(“”)を指定して削除していますが、別の文字列に置換することも可能です。
数字だけ抜き出す(文字だけ消す)方法
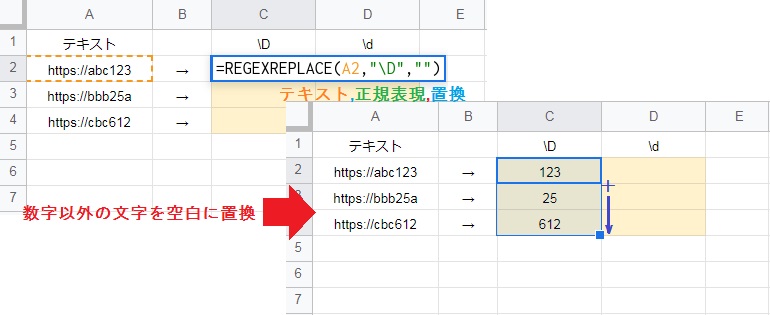
REGEXREPLACE関数は指定した正規表現に従って、テキストの一部を新しい文字列に置換します。
例えば “\D” は、数字ではないこと表す正規表現です。REGEXREPLACE(A2,”\D”,””) はテキスト内の数字ではない文字を空白に置換するので、数字だけが抽出できます。
REGEXREPLACE関数の構成要素:(テキスト, 正規表現, 新しい文字列)
数字だけ消す(文字だけ抜き出す)方法
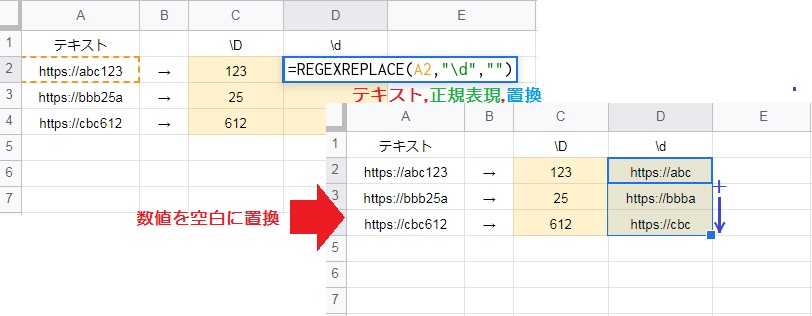
数字だけ消す場合は、数字であることを意味する正規表現 “\d” を使用します。
つまり REGEXREPLACE(A2,”\d”,””) はテキスト内に含まれる数字を空白に置換するので、文字列だけを抽出できます。※二重引用符の付け忘れに注意してください。
| 正規表現 | 説明 |
| […] | 角括弧内のすべての文字 |
| [^…] | 角括弧内の文字を除くすべての文字 |
| \d | すべての数字 |
| \D | 数字を除くすべての文字 |
| \s | 空白 |
| \S | 空白を除くすべての文字 |
数式から数字(値)だけをコピーする方法
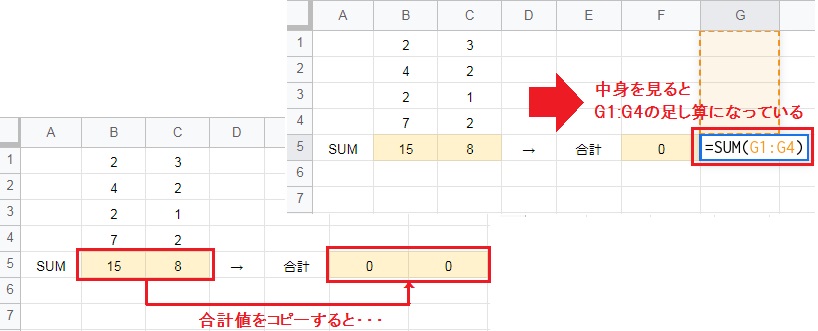
例ではSUM関数の合計値をコピーして別のセルに貼り付けていますが、貼り付け先の値がゼロになってしまいました。セルの中身を確認すると、G1:G4 の足し算になっています。
これはエラーではなく、通常の貼り付けでは今回のように数式がコピーされ参照も移動します。

合計値の数字だけを貼り付ける場合は、まず通常通りセルをコピーします。
次に貼り付け直後に表示されるセルの右下のオプションから、「値のみ貼り付け」を選択してください。中身を確認するとコピー元は数式ですが、貼り付け先は値になっています。
コピーするショートカットキー:[Ctrl]+[C]
値のみ貼り付けるショートカットキー:[Ctrl]+[Shift]+[V]
