
Googleスプレッドシートのデータ抽出に便利なQUERY関数について、前回は基本構成やSELECT句の使い方を詳しくご紹介しました。

QUERY関数No.1
- QUERY関数とは
- 基本的な構成
- SELECT句の使い方
今回はデータの抽出条件を指定できる「WHERE句」について、基本的な使い方や複数条件を指定する方法をご紹介するので、ぜひ参考にしてみてください。
スプレッドシートのQUERY関数の使い方
QUERY関数ではGoogle Visualization API のクエリ言語を使用することで、様々な方法でデータ抽出が可能です。QUERY関数の要素と、クエリの種類についておさらいしましょう。
QUERY関数とは?

QUERY関数は対象の「データ」範囲に、指定した「データ操作(クエリ)」を行います。
クエリはデータに対して実行する「処理・命令」のようなイメージです。
クエリにはそれぞれ異なる機能を持つ10種類の句が用意されており、各クエリや関数を組み合わせることで様々な方法でデータ抽出することができます。
QUERY関数の構成要素:(データ, クエリ, [見出し])
QUERY関数のクエリの種類

クエリの種類には以下のようなものがありますが、今回はWHERE句について詳しく解説します。WHERE句は代表的なクエリで、SELECT句で抽出する列に対して条件を指定できます。
- select :特定の列を指定した順序で抽出します。
- where :条件を満たすセルだけを抽出します。(ピックアップ)
- group by: 列内の同じ要素の値を集計します。
- pivot :group byで抽出したデータに分類要素を追加します。
- order by 行を列の値で並べ替えます。
- limit :抽出する行数を指定します。
- offset:指定した数の最初の行をスキップします。
- label:列ラベルを設定します。
- format:特定の列の値を書式設定します。
- options :追加オプションを設定します(no_formatまたはno_values)
QUERY関数のWHERE句の基本的な使い方
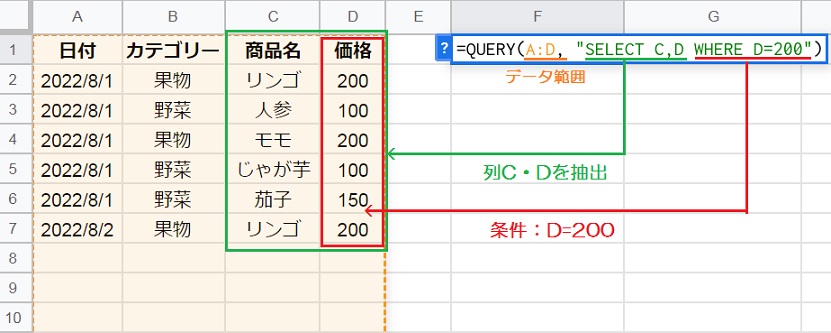
QUERY関数のWHERE句は、指定された条件に一致する行のみを抽出するために使用します。
例えば「=QUERY(A:D,”SELECT C,D WHERE D=200″)」のように、D列が200であるという条件をし指定して、SELECT句でC列・D列を抽出してみましょう。
比較演算子:以下(<=)、より小さい(<)、以上(>=)、より大きい(>)、等しい(=)、等しくない(!=)または(<>)、空白でない(is not null)、空白(is null)
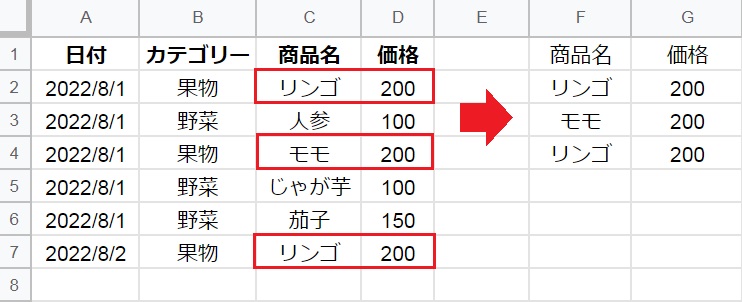
SELECT句に指定したC列・D列のうち、条件(D=200)と一致する行だけが抽出されました。
※条件に文字列を指定する場合、文字列を’シングルクォーテーション’で囲います。
WHERE句の構成:=QUERY(データ範囲, “SELECT 列1,列2… WHERE 判定式“)

QUERY関数のSELECT句は、省略することも可能です。
=QUERY(A:D,”WHERE D=200″)のようにSELECT句を省略(またはアスタリスクを指定)した場合、データ範囲から指定した条件と一致するすべての行を抽出します。
QUERY(データ範囲, “WHERE 判定式“)または(データ範囲, “SELECT * WHERE 判定式“)
WHERE句に複数の条件を指定する方法
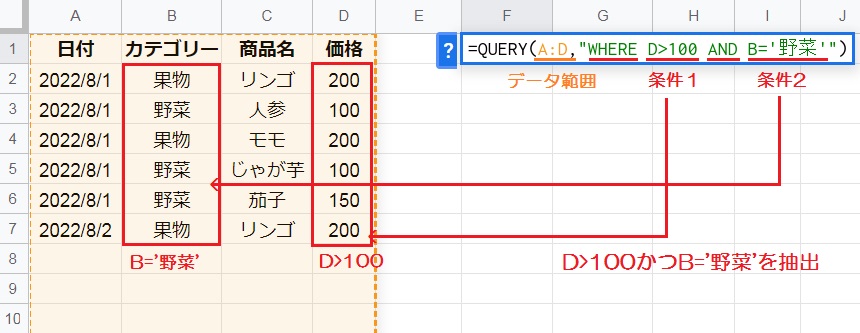
論理演算子を使えば、WHERE句に複数の条件を指定することも可能です。
条件をすべて満たす場合にのみTUREを返す「AND」を使用して、2つの条件を指定してみましょう。
※なお今回の例では、SELECT句を省略しています。
論理演算子:論理積(AND)、論理和(OR)
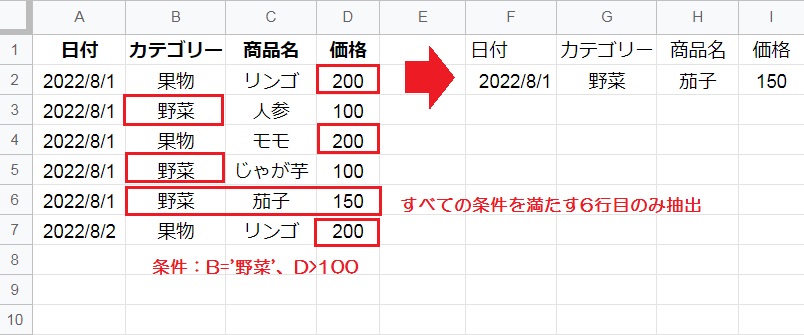
「=QUERY(A:D,”WHERE D>100 AND B=’野菜'”)」のように、条件1にD列が100より大きい、条件2にB列が野菜であるという条件を指定します。
対象のデータ範囲から、条件を2つとも満たしている6行目のデータだけが抽出されました。
複数条件を指定:=QUERY(データ範囲,”WHERE 条件1 AND 条件2“)
WHERE句で文字列を検索する複雑な演算子
WHERE句に指定する文字列の比較演算の中から、特に知っておきたい3種類について解説します。文字列の比較では大文字と小文字は区別されるので注意しましょう。
- contains:部分文字列の一致を判定します。
- starts with:対象データが条件文字列で始めるかを判定します。
- ends with:対象データが条件文字列で終わるかを判定します。
- matches:正規表現と一致するか判定します。
- like:ワイルドカードを使用して部分一致を判定します。
CONTAINS(部分文字列を含む)
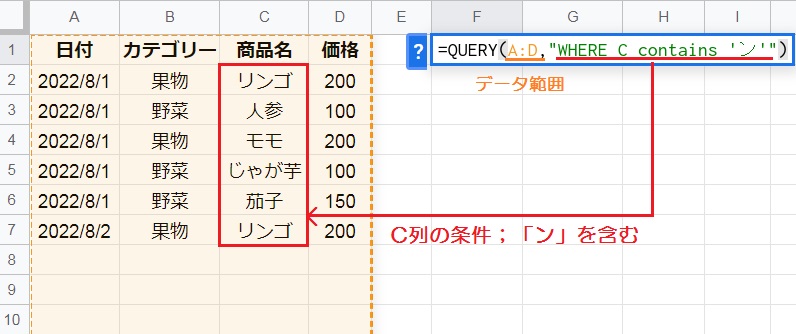
WHERE句にはより複雑な、特定の文字列を抽出する比較演算子を指定することも可能です。
例えば「=QUERY(A:D,”WHERE C contains ‘ン'”)」のように、C列が文字列「ン」を含む、という条件を満たす行だけを抽出してみましょう。
contains: 部分文字列の一致を判定します。指定した文字列が対象データ内のどこかにある場合、contaisはTRUEを返します。
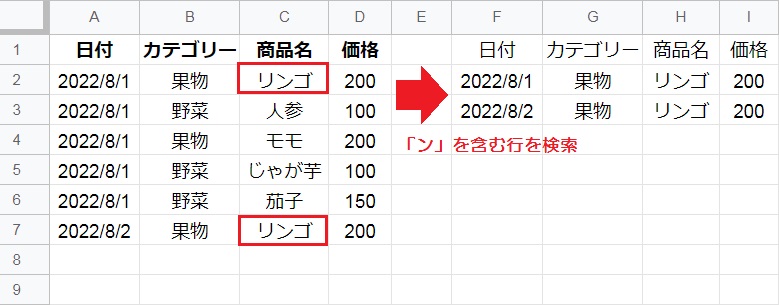
対象のデータ範囲から、C列に「ン」を含む2行目と7行目だけが抽出されました。
contains:=QUERY(データ範囲,”WHERE 列 contains ‘文字列‘”)
MATCHES(正規表現と一致)
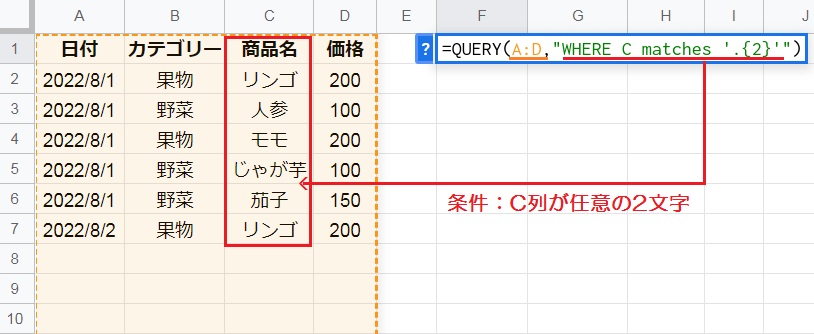
MACHTESは指定した正規表現(記号を用いた文字列のパターン)と一致する場合に、TRUEを返します。
例えば「=QUERY(A:D,”WHERE C matches ‘.{2}'”)」のように、C列が任意の2文字である、という条件を満たす行だけを抽出してみましょう。
基本記号:任意の1文字( . )、n回の繰り返し{n}、0回以上の繰り返し( * )、1回以上の繰り返し( + )、先頭の文字列( ^ )、末尾の文字列( $ )
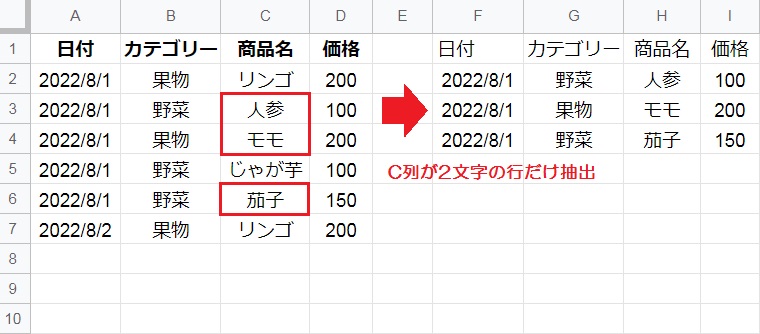
対象のデータ範囲から、C列が任意の「2文字」で構成さる3,4,6行目が抽出されました。
matches:=QUERY(データ範囲,”WHERE 列 matches ‘正規表現‘”)
LIKE(部分一致)
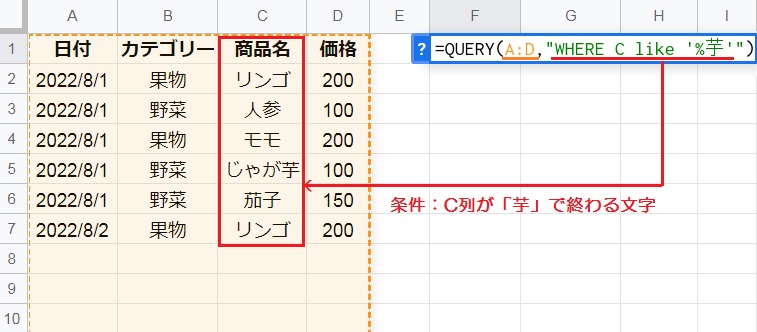
LIKEはワイルドカード(代替文字)を使用して、部分一致(前後または中間)する文字列を検索できます。
例えば「=QUERY(A:D,”WHERE C like ‘%芋'”)」のように、C列が芋で終わる任意の文字、という条件を満たす行だけを抽出してみましょう。
ワイルドカード: 任意の0 個以上の文字( % )、任意の 1 文字( _ )
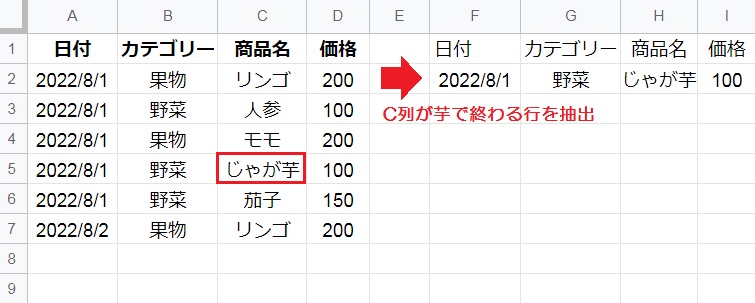
対象のデータ範囲から、C列の末尾が「芋」と一致する5行目だけが抽出されました。
任意の文字列で始まる場合は「○○%」、任意の文字列を含む場合は「○%○」で表現できます。
like:=QUERY(データ範囲,”WHERE 列 like ‘..%‘”)

QUERY関数No3
- GROUP BY句の使い方
- PIVOT句の使い方
- クロス集計

